ARDN
Data Provider Workflow for Ag Data Commons
The diagram below presents a typical workflow for an ARDN data provider sharing data through Ag Data Commons (ADC).
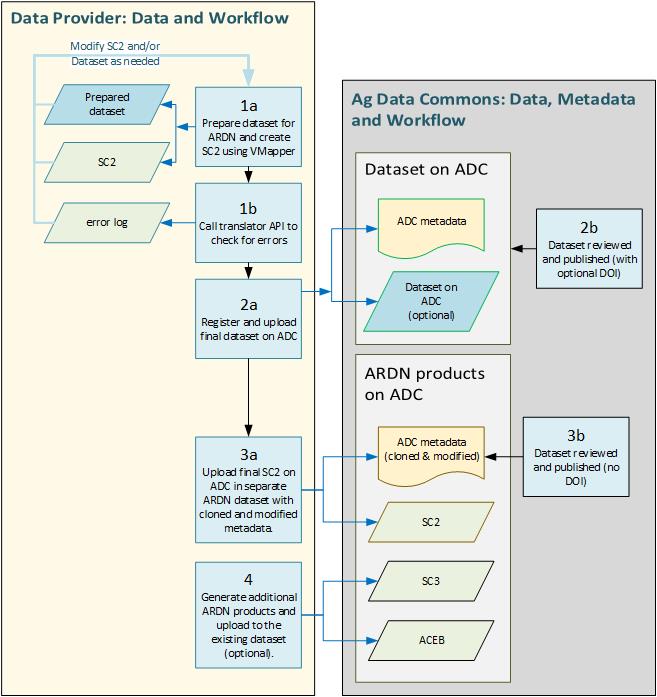
Step 1. Data preparation
A researcher wanting to ARDN-ize their data would first prepare the data for archiving on their local computer or server. If the dataset has already been archived on ADC, this step may not be necessary. However, for complex datasets, some data manipulation may be required in order to establish relational linkages within the dataset, which is a necessary element of ARDN.
-
We strongly suggest the use of Tidy Data principles for preparing datasets to be used for any type of analyses. Links to tidy data paper and other useful information can be found here.
-
VMapper is used to map the variables in the dataset to the ICASA vocabulary terms. The units of the raw data are declared so that they can be converted to ICASA-compliant units at the time of translation.
-
The end result of VMapper is a Sidecar 2 file or SC2, a data annotation file in JSON format. This is may not be the final version of SC2 as it does not yet contain the links to the dataset archived on Ag Data Commons.
Step 2. Upload and publish on Ag Data Commons
When the dataset is prepared and annotated, it can be registered and uploaded to Ag Data Commons. (First your must register for a free account on Ag Data Commons.) A very clear Data Submissions Manual is provided to assist users in the process of creating metadata and uploading data files. The user decides when the metadata and dataset are ready for review.
The metadata goes through a curation review process and when ready, the dataset is published and a DOI is assigned (optional).
Step 3. Finalize, upload, and publish the SC2 dataset
Once the dataset has been published and a DOI assigned, the SC2 file can be modified to include the actual link to the dataset on Ag Data Commons. This step is optional because the SC2 file could also be applied to the downloaded dataset on a local computer drive rather than accessing it directly from Ag Data Commons at the time of translation.
A new dataset is created for the SC2 and other associated ARDN products by cloning and modifying the metadata from the original dataset. See the detailed “Steps to creating an ARDN Products dataset”.
Step 4. Additional ARDN Products
Additional ARDN products can be optionally created and uploaded to the ARDN Products dataset.
- SC3 - The sidecar 3 file includes a sub-set of the dataset which can be used by Ag Data Commons for advanced search functions.
- ACEB - AgMIP Crop Experiment Binary files contain the data in a compact AgMIP format, readable by the AgMIP translators.
Eventually, generation of SC3 and ACEB files could be done in an automated step, but currently, this must be done manually. These additional files are added as Resources to the ARDN Products dataset as described in “Steps to creating an ARDN Products dataset”.
Model-related files associated with the dataset may also be added to the “ARDN Products” dataset. These include
- model-specific DOMEs,
- linkage files,
- model-ready input files, and
- model outputs.
These files should be zipped together as a single upload. It is possible to have multiple sets of model-related files for different models or for different modeling assumptions (DOME files).